


The IT domain is too often treated as a “nice to have, if time allows.” Yet, using it as a proof of concept to redesign your data strategy can bring a lot of value.
It gives you the opportunity to define and shape the right measures to monitor platform teams;
It naturally fosters cross-functional collaboration, as it is a transversal domain in the organisation;
It drives the implementation of governance practices between product and tech teams;
Finally, it establishes clear ownership within the digital space, with stewardship anchored in IT.
As an IT team, if you can’t succeed in applying a Domain-Driven approach to your own data, how can you expect to extend it to the business?
In this article, we will focus on how DDD applies to engineering practices through a transversal IT domain, and what this means for platform teams and enabling capabilities.
The IT domain to transform IT teams first
This article is meant to be read by product managers, data architects, data engineers, platform teams, security, DevOps or technical leads. All the people in charge of ensuring a high level of SLA on their applications, maintaining and scaling architectures.
The IT data domain is your key to scale your IT architecture. It will indirectly serve your external business lines by equipping your internal support teams with a single vision of your application patrimony. Operational resilience is ensured by enabling the collection and management of the following data across the organization : system logs, system observability, employee data, and service monitoring.
What we will do together in this article (that is definitely a bit long):
A high level discovery of the functional domain
A detailed refinement of the development and delivery processes
A detailed formalisation of the CI/CD process
And finally the bounded context we will implement
Discovery: solving engineering problems makes your business happy
Discovery is about getting to know how things operate in the company, who operates them and why. It will help you find how you can serve teammates and what will be the main focus of your team moving forward. It starts by listing the processes that generate the data we want to acquire from sources, the main objects that we will want to retrieve from the sources and the main processes we want to animate.
What are the IT domain business processes?
Here is a proposition of a list of business processes we often see in companies IT domains, it is non-exhaustive. We will be for the rest of the article interested in details in the processes pertaining to development and delivery. (Management will be written Mgt for the rest of this paragraph.)
Strategy & Governance
Portfolio Mgt: Managing investments in IT projects and applications.
Architecture Mgt: Defining and maintaining the enterprise architecture.
Governance & Compliance: Ensuring regulatory compliance and risk management.
Service Management (ITSM)
Incident Mgt: Handling IT service interruptions and restoring service.
Service Level Mgt: Defining and monitoring Service Level Agreements.
Operations
Infrastructure & Platform Mgt: Operating infrastructures and networks.
Monitoring & Event Mgt: Ensuring availability and performance through monitoring.
Backup & Recovery: Safeguarding data and ensuring continuity in case of failure.
Development & Delivery
Requirement Mgt: Gathering and prioritizing business needs.
Software Development: Designing, coding, testing, and deploying software.
Test Mgt: Ensuring quality through test plans and test execution.
Continuous Integration /Continuous Delivery: Automating code integration and deployment.
Security & Risk Management
Access Mgt: Controlling user access to systems and data.
Information Security Mgt: Protecting data confidentiality, integrity and availability.
Risk Mgt: Identifying and mitigating IT-related risks.
Cybersecurity Incident Response: Responding to threats and breaches.
Support & User Enablement
Help Desk and Service Desk: First-line support for users.
Knowledge Mgt: Providing documentation and FAQs to support users.
Training & Onboarding: Helping users adopt new tools and technologies.
While describing each process, there are 3 things to consider in particular:
● Which processes are critical?
● Which processes are data dependent?
● What are the main indicators to monitor if the process is operated correctly?What are the main data producers?
Digital products are supported by an interconnected ecosystem of tools (technical stack) that structure the entire lifecycle, from idea to production.
It begins with product and planning platforms such as Jira or Azure DevOps, where product managers translate requirements into epics, stories, and sprints. Once direction is set, development teams rely on code repositories like GitHub or GitLab to store and manage source code, supported by tech leads and DevOps engineers. From there, CI/CD pipelines, powered by Jenkins or GitHub Actions, automate builds and deployments. Quality is safeguarded by testing tools such as TestRail or Xray, operated by QA engineers. The outputs are captured in artifact repositories like Docker Hub, ensuring secure and reliable storage. To run applications across development, test, and production stages, teams depend on environments and infrastructure hosted on AWS, Azure, or Kubernetes, often maintained by platform engineers. Once in production, monitoring and logging solutions such as Grafana or Datadog provide critical visibility into health, errors, and performance, enabling site reliability engineers to keep systems stable. Access management tools like Vault or AWS Secrets Manager ensure that credentials and permissions are securely handled by security teams.
We have described in a few words the ecosystem that animates the collaboration between product, development, operations, and security and makes modern digital organisations run. These dynamic structures evolve constantly with business needs, practices, technological improvements and management changes.
We call legacy, both the code that is already pushed and the solution that is in place and expected to evolve. This legacy has to be refactored and to evolve towards new visions. This continuous improvement creates constant change: processes, sources and data. The source responsibility is of utmost importance to avoid incidents and breaking changes.
While describing each source, there are 3 things to consider:
● Are product teams close to the application models?
● Are operational teams considering how their data is used outside of their team?
● Do you have quality practices already in place in the application?What are the business entities within the IT domain?
From this first exploration, we can already list and describe some of the business entities and their possible relationships. Mapping this information is important to have a first alignment on ubiquitous language.
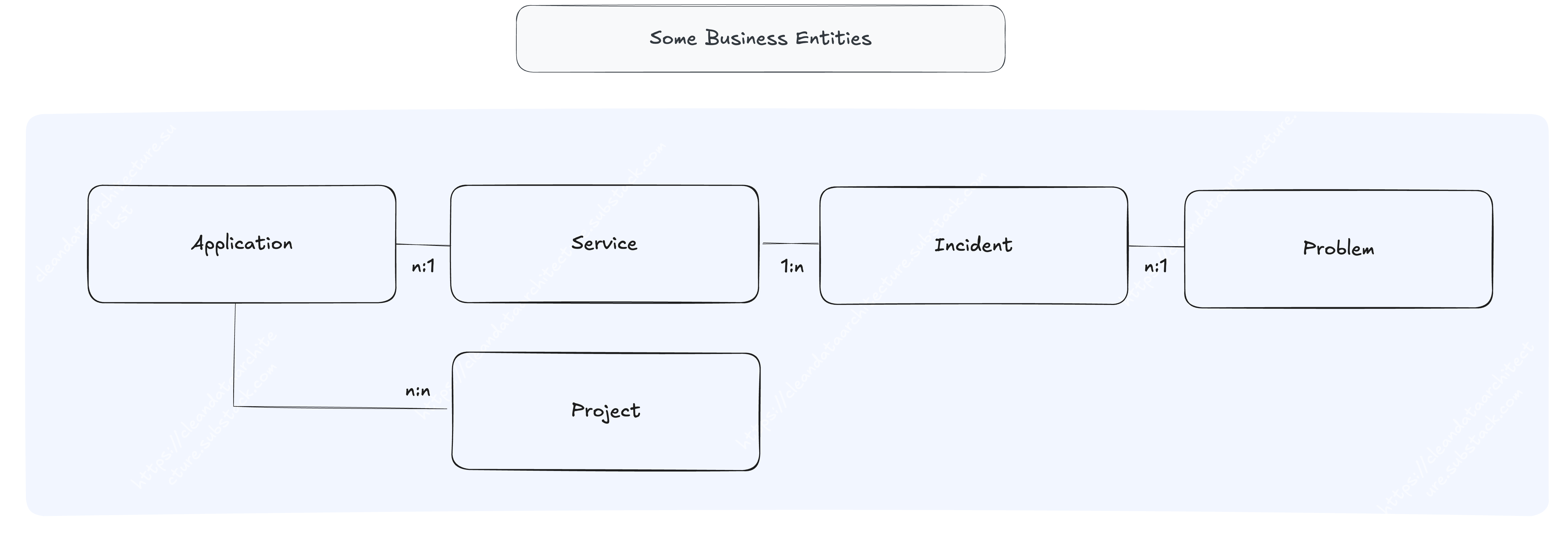
Application: a software and data engineering program or suite that supports one or more business functions or IT services.
Service: a set of IT capabilities delivered to a customer or user that provides value and supports business processes.
Incident: An unplanned interruption or reduction in the quality of a service.
Problem: The underlying cause of one or more incidents.
Project: A temporary effort undertaken to build or improve a service.
We are especially interested in mapping the discrepancies between different domains and processes. If the discrepancies exist are they justified? Or do we need to align the language? An example: the word “Product” that often does not appear in governance and ITSM processes but exists in the team's daily collaboration. Without aligning the language, you can see how handling budgets for “run” and “build” can become a nightmare at scale.
How do you convince your CFO to let teammates work on the ubiquitous language? Next year when you kick-off budget processes, compute the cost of all budgeting meetings, collect teams questions in a single spreadsheet and create a Net Promoter Score. Your process is now ready to be improved drastically.
Let’s have a look at some use cases
Use cases should definitely be investigated with a cross-domain approach. Here are some additional use cases for supporting processes outside of the IT domain:
Operations & Customer Service could use the real-time access to API & service status to respond to customer issues: Service Health Monitoring.
The Finance & Procurement processes could need the Cost per Deployment / Feature in order to track cloud costs per team or product based on CI/CD metadata.
The Security team would need Automated Vulnerability Scanning: Integrated into CI/CD, alert security teams instantly to operate SecOps and Compliance processes.
To support architecture & governance, a Service Catalog Auto-Generated from CI/CD could help architects track tech sprawl and dependencies.
What have we learned from this discovery?
Through our discovery, we gained a deeper understanding of how engineering processes influence business outcomes.
Sometimes the outcome of a discovery will validate what you already know: efficient development and deployment impact internal stakeholders’ satisfaction and the organisation’s ability to deliver value in a timely manner.
But the deliverables created along the way, for example the data mapping reveals where data is generated, who operates it, and how it flows across the organisation. It brings an essential visibility for identifying bottlenecks, clarifying accountability, and reducing operational and financial risks.
The clarification of ubiquitous language and use cases discovery helps you identify critical metrics that serve as early indicators of process quality and financial impact. For example, tracking incident resolution times, SLA breaches, deployment failures, and risk exposure allows leaders to make informed decisions that optimize costs, minimise downtime, and improve predictability of investments in technology.
You also learn that IT data does not exist in isolation. Insights from delivery, deployment, and monitoring processes support cross-domain functions such as finance, operations and architecture.
Finally, you understand priorities and what focus you should choose, especially if you are starting from scratch. In this fictional case, focusing on delivery and deployment processes, requirements, development, testing, CI/CD, and release management, emerged as a priority. These areas have the most direct influence on product quality, time-to-market, and operational efficiency, making them key levers for business performance.
Refinement: Tell the story and design the solution
Now that you have discovered a lot of stuff, the refinement preparation is a storytelling exercise: the objective is to summarise what you have learnt, the problem faced and the key take-aways, in a way that focuses on the people flowing across the organisation.
In this article we chose for each process to describe the actors, some of the inputs necessary for operation and the outcomes of the process delivery. For the sake of this example, the word “solution” is referring to a set of applications pertaining to a service and responding to a requirement.
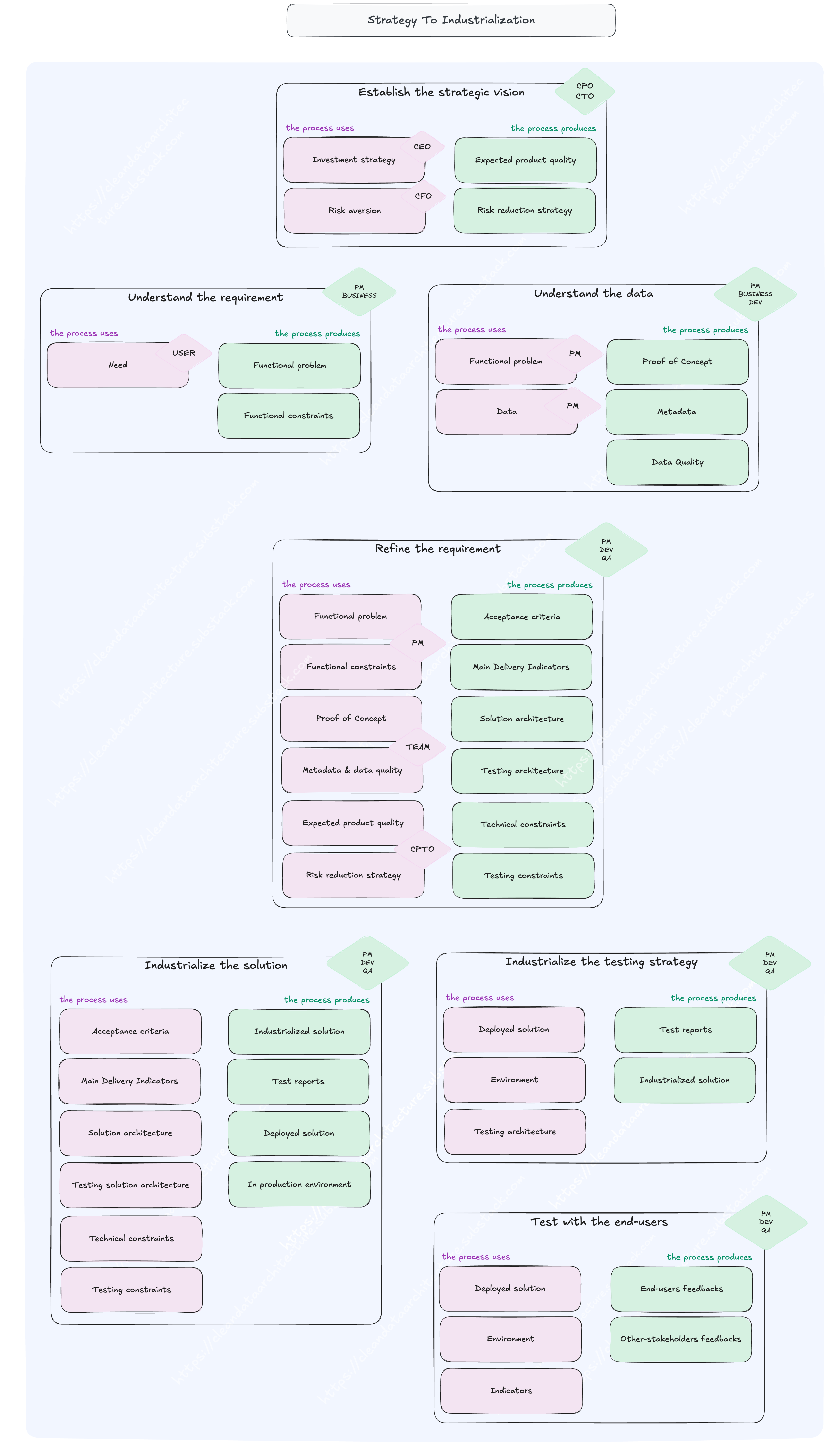
Model as a first class citizen
IT Domain Strategic Goal
Our Domain Strategic Goal is to: “Ensure fast, safe, and reliable delivery of software to production.”
We are then especially interested in the continuous integration and delivery process that automates the entire flow from code commit to production release. This process ensures that application changes are integrated, tested, and deployed reliably and frequently. It supports rapid iteration, fast feedback loops, and production stability.
This process has a strong operational criticality as a broken CI/CD pipeline can cause delays in feature delivery or hotfixes, manual errors in releases, developer frustration, wasted time and increased risk of production incidents. It’s especially essential for the following end-users daily team delivery routines, production readiness, and fast recovery in case of failures.
Activities happening during the process
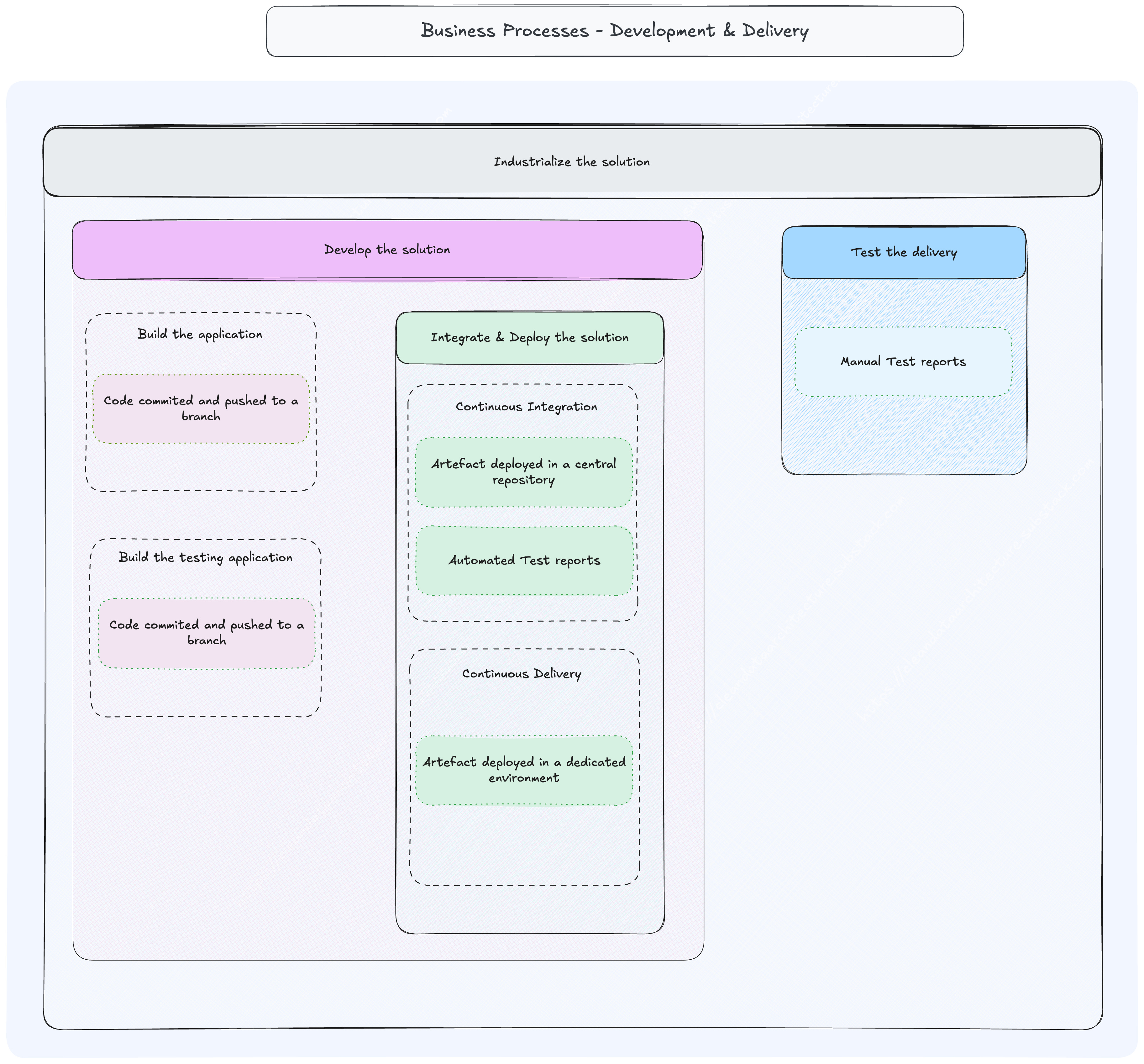
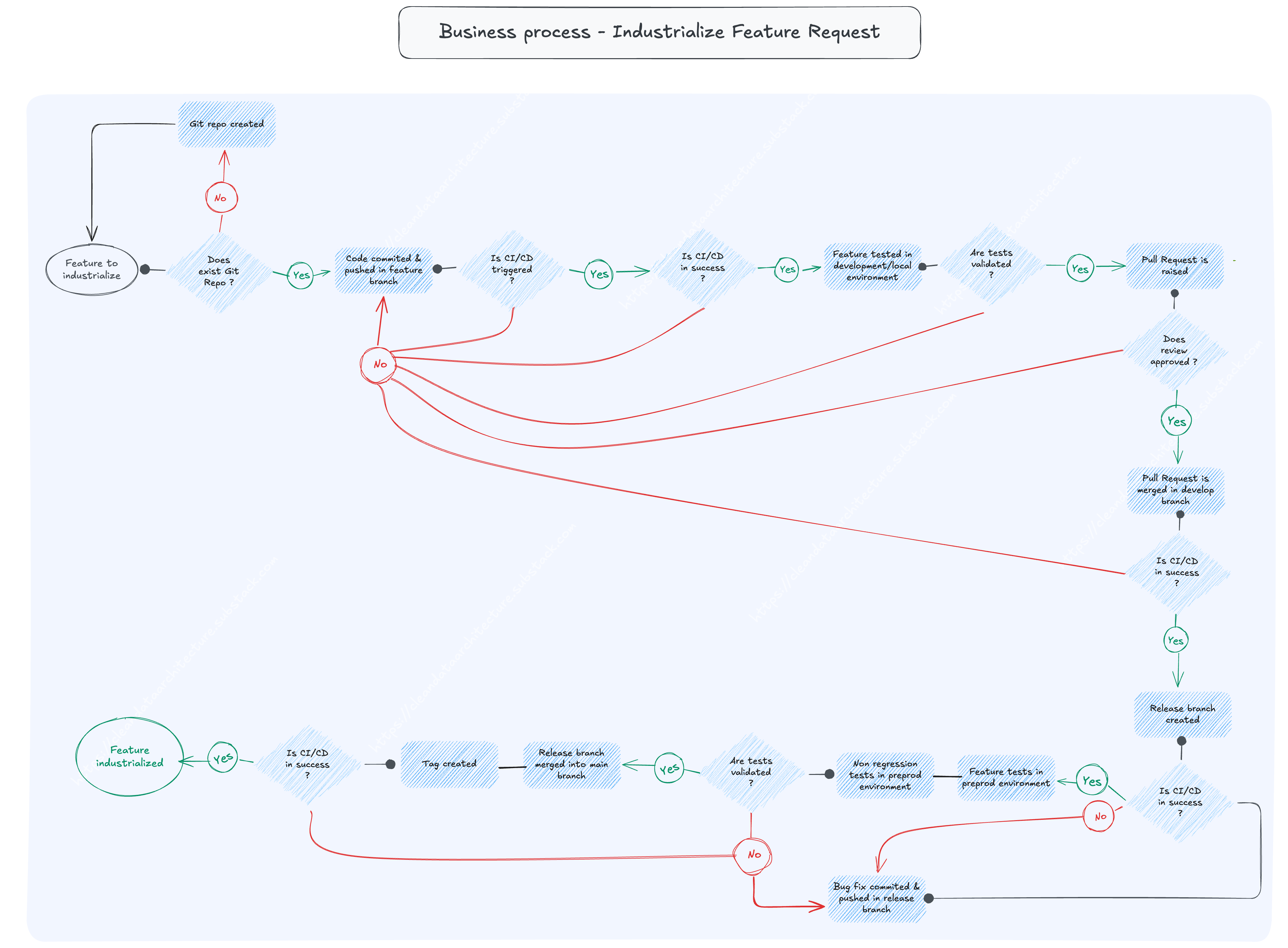
Detailed tasks and decisions
Detailed data mapping
We summarise our main data sources for these processes in the following list:
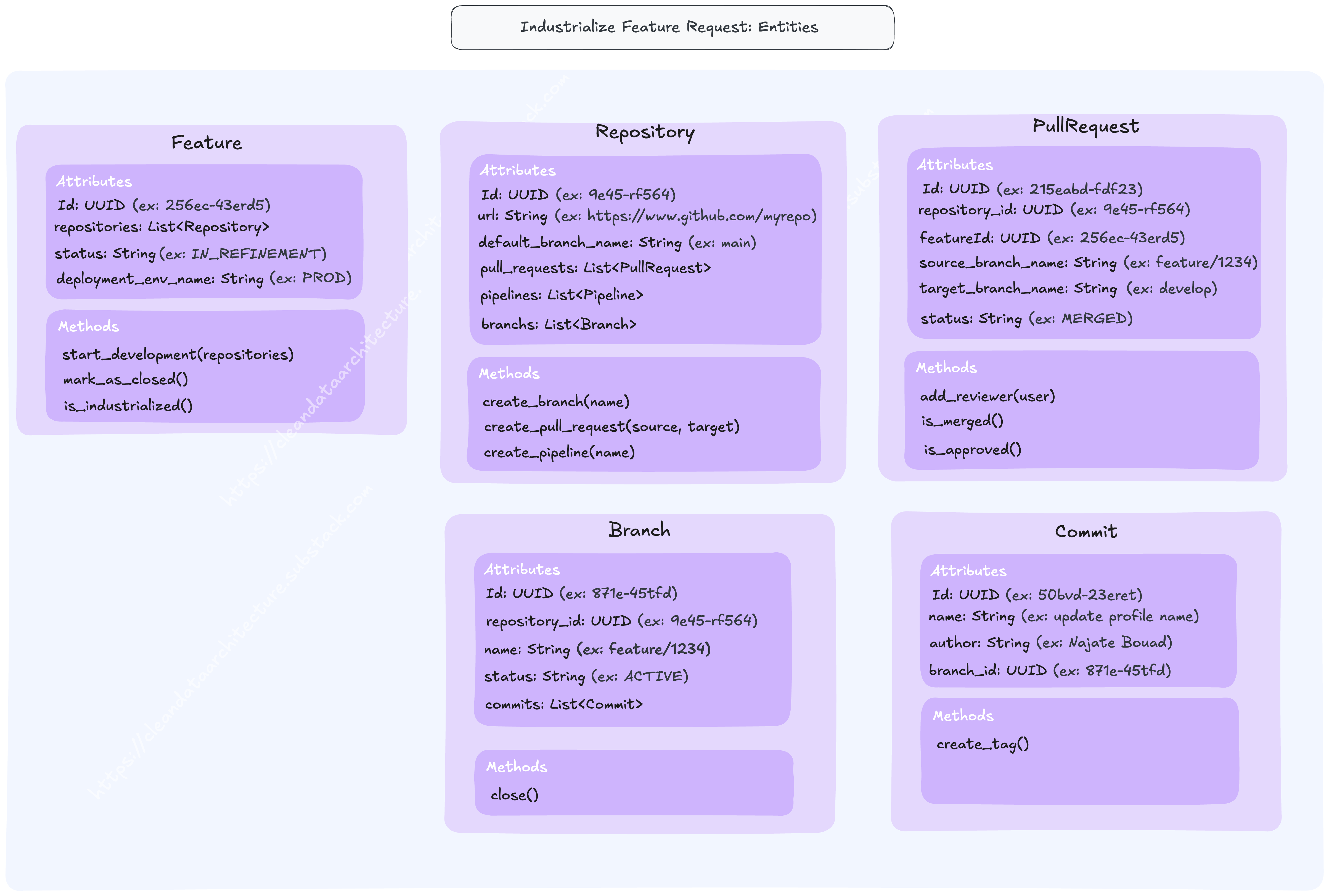
Code & Versioning | Commit; Pull Request; Branch Merge | Github; Gitlab
Feature Tracker | Feature metadata; Name; Status; Link with code | Jira; Github Issue
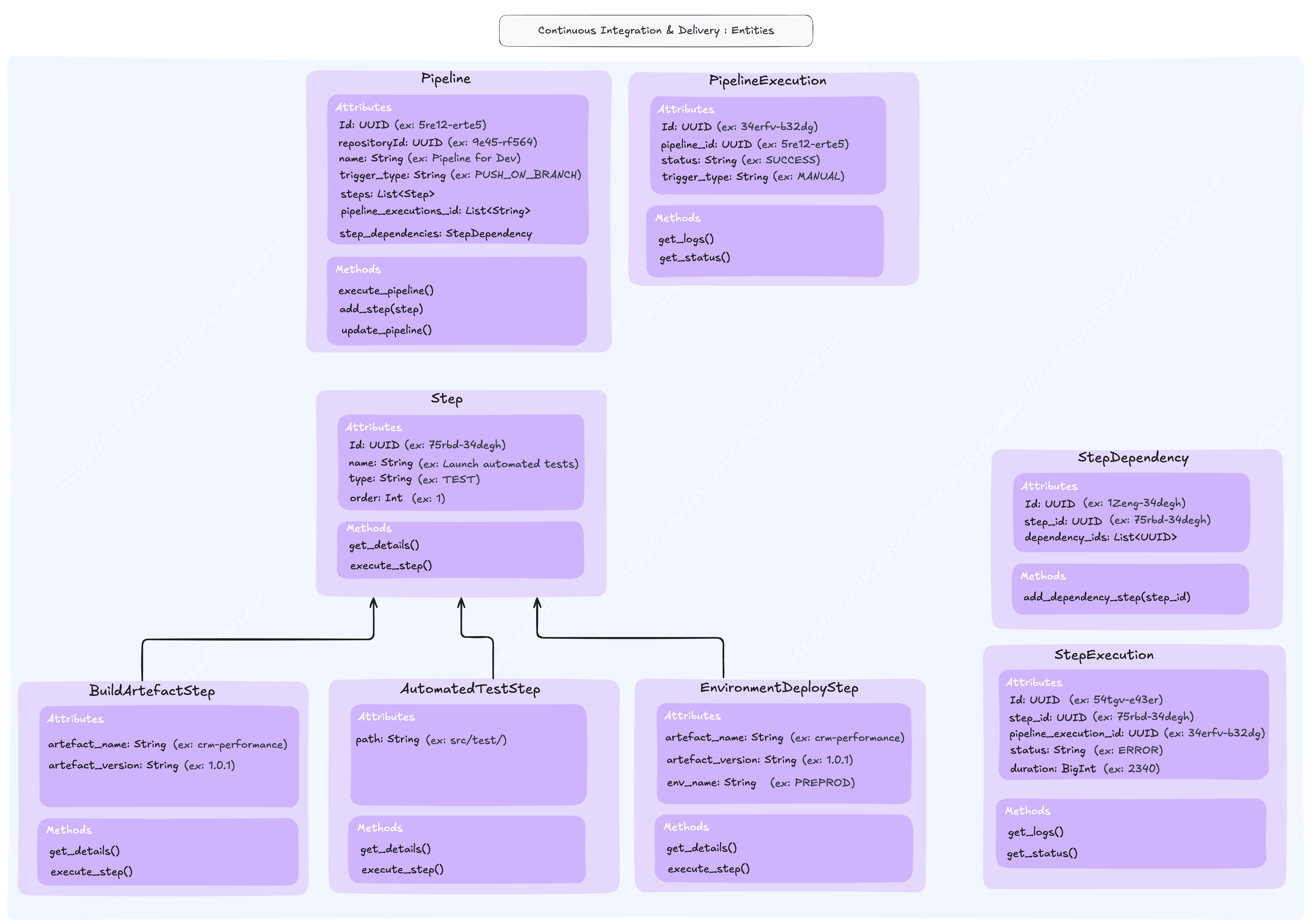
Pipeline CI/CD | Pipeline definition; Pipeline execution; Step definition; Step execution | Github Action; Jenkins; Travis
Artifacts | Binary; Package; Version; Author | Nexus; Artifactory; Docker Registry
Tests & Quality | Test résult; Code coverage; Vulnerability alert; Quality rule | SonarQube; Testrail; XRay
Bounded Context
Overview
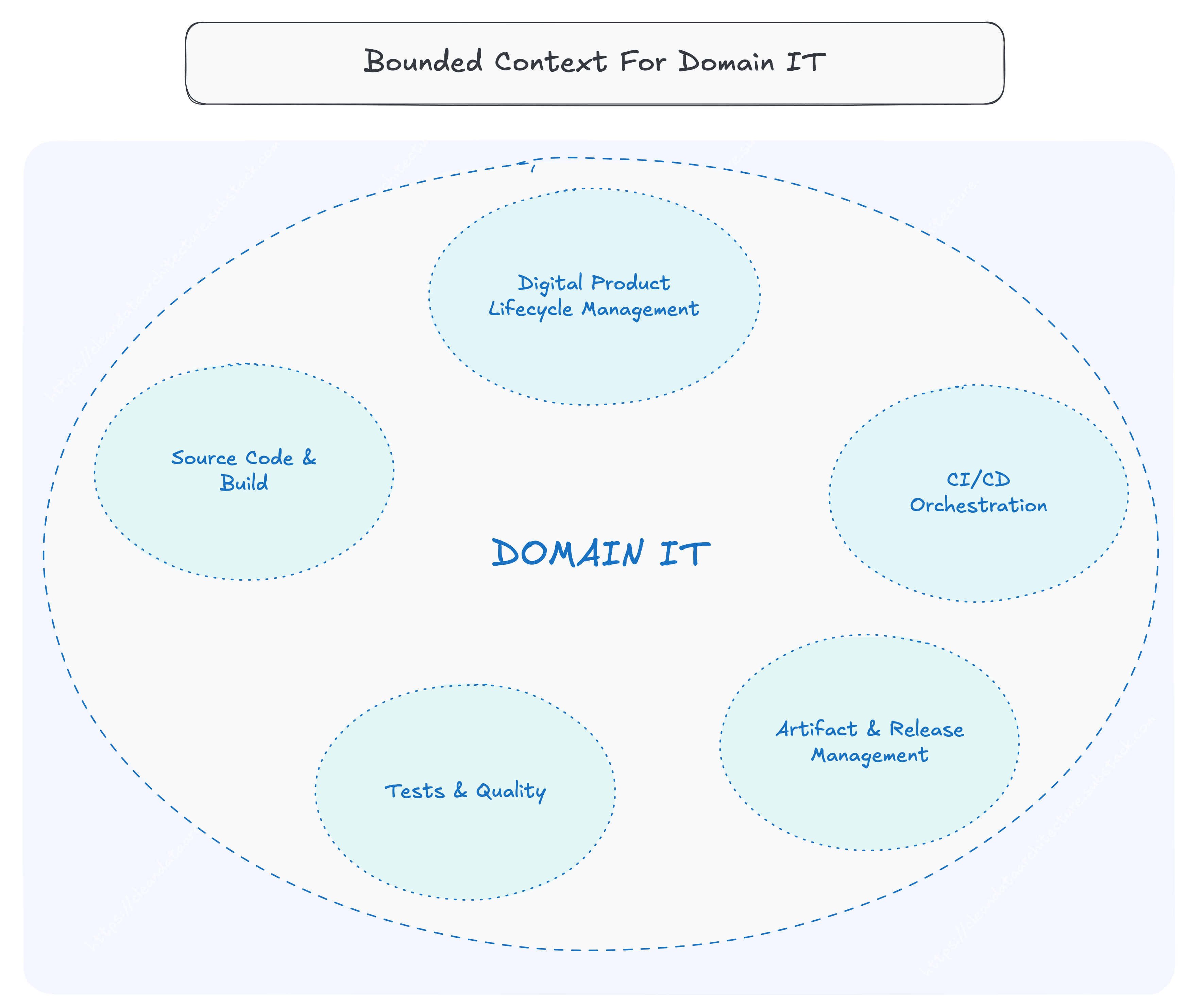
Entities
Policies or business rules
Policies will be interesting to identify for creating your quality rules, either in the sources directly or at the consumption layer. Some examples include:
The feature industrialisation can start only if its status is Ready To Develop.
The deployment in PROD can be done only if there is a merged Pull Request in main branch.
The deployment in Preprod can be done only if there is a push in a release branch.
Read Models and Projections (for dashboards, queries)
Here we are interested in what your consumption looks like? What are the main use cases you want to develop?
Deployment Status Overview: Show all deployments by environment and status
Pipeline Health Dashboard: Average build time, failure rates
Delivery Metrics Dashboard: Lead time from ideation to deployment, Time to release Vs Time To Market
Digital Product Performance: As a C-level, I want to be able to monitor the performance of applications relative to the budget spent during the year.
The good thing is, for each of one you will have to do a discovery to understand your persona and how to serve them the data: fun never stops 😀
Key Metrics
What are the key metrics that you will want to compute and serve to your users? Are some of them necessary across different use cases?
Deployment Frequency: how often new code is deployed in Prod
Lead Time for Feature Delivery: time from the start of development to production deployment
Release Frequency: number of release candidates
Release Stability: number of releases without rollback/hotfix
Pipeline Execution Rate: % of successful execution pipeline
Test Coverage: % of code covered by automated tests
Pipeline Duration: pipeline execution time
Rollback Count: how often releases are reversed
Proposed data architecture
In this ongoing journey, this particular deliverable is without doubt the most rewarding one to design and present. Writing this article, we invested hours capturing our reasoning in the clearest way possible and we truly enjoyed drafting these final lines.
As DDD reminds us, such a deliverable is never static. It will evolve alongside your ecosystem, your business priorities, and your collective understanding. It also requires continuous care and maintenance. Still, it stands as a cornerstone for impact management (a process that we didn’t describe here now that we think about it!).
This output is designed to be shared widely, across both data and digital teams. Notice how we no longer separate operational and analytical layers: the data domain exists as a functional construct, regardless of which team is responsible for operating it.
Even when data products live within existing platforms, these deliverables can serve as inspiration, encouraging teams to consolidate aggregated products and even build digital applications that manage their own indicators.
The benefits of this approach are so inspiring to us, Gaëlle and Najate. And if you are not convinced after reading us, we still hope this gives you a clear sense of our perspective and of the direction we want to pursue when applying DDD from strategy to execution.
For the IT domain, the benefits are clear: autonomy enabled by explicit contexts, the ability to design and scale standardised schemas, establish observability contracts, and expose domain APIs. To wrap it up with a playful (and admittedly imprecise) formula: DDD in tech domains = agility + traceability.
Stay tuned for the next article from engineering to architecture in the Sales domain.
Mostly impressive article. It's a modern how-to standard for every company! Great work
Very great work. Everything we need to lnow before building a data architecture.